
How to Think About ChatGPT
a basic understanding of how LLMs work


Special thanks to Dr. Roller Gator for his help. His Substack is here. He doesn’t write often, but every time he does it’s an instant classic. You should subscribe!
Recently, some of the parents I help with their homeschooling curriculum have started relying on chatGPT in a way that’s not going to serve their kids. They trust chatGPT’s answers, think of it as an entity that can make deductions and come to conclusions, and otherwise are relying on it as if it’s a source of knowledge.
I get why they’re doing it. LLMs like chatGPT provide what seems like definitive answers to questions, and really give the impression of thinking and reasoning, even though they do absolutely nothing of the kind.
The point of this post is to explain how chatGPT works so that you can approach Large Language Models (LLMs) like chatGPT for the tools that they are, and not try to use them inappropriately.
A note on terms: I’m going to say LLMs throughout this post even though many people say “AI” when they are referring to LLMs. Saying “AI” for LLMs is indicative of a lack of understanding. And even though I may long-term lose the battle for the generic (people may say “AI” for LLMs, sort of the way that people say “Kleenex” for all tissues, whether they’re talking about Kleenex brand tissues or not) I will not concede that point in this essay.
LLMs are a subset of Artificial Intelligence only. Facial recognition, self-driving cars, and computer vision — systems that let computers see cancers on scans that are as of yet too small for a human to notice — are just three of the many other types of AI.
Fear Not
This is not going to be a highly technical explanation. And it is not going to be difficult for you to understand.
It’s going to give you the gist of it. In the same way that “sex between a man and a woman makes babies because, as a result of sex that happens at the right time in the woman’s cycle, the man’s seed fertilizes the woman’s egg and then the fertilized egg slowly grows into a baby” is a basic understanding of reproduction—and the difference between an ovary and a fallopian tube isn’t important to understanding that—this will give you a basic understanding, not a technical one.
To start off, I’m going to give you five simple concepts to wrap your head around, then show you how those concepts combine in the operation of LLMs.
Simple Concept 1: Dimensions
This is a line:

This is a square. You might say we squared the line:

This is a cube. We squared the square, so now it has six sides, including the bottom and top:
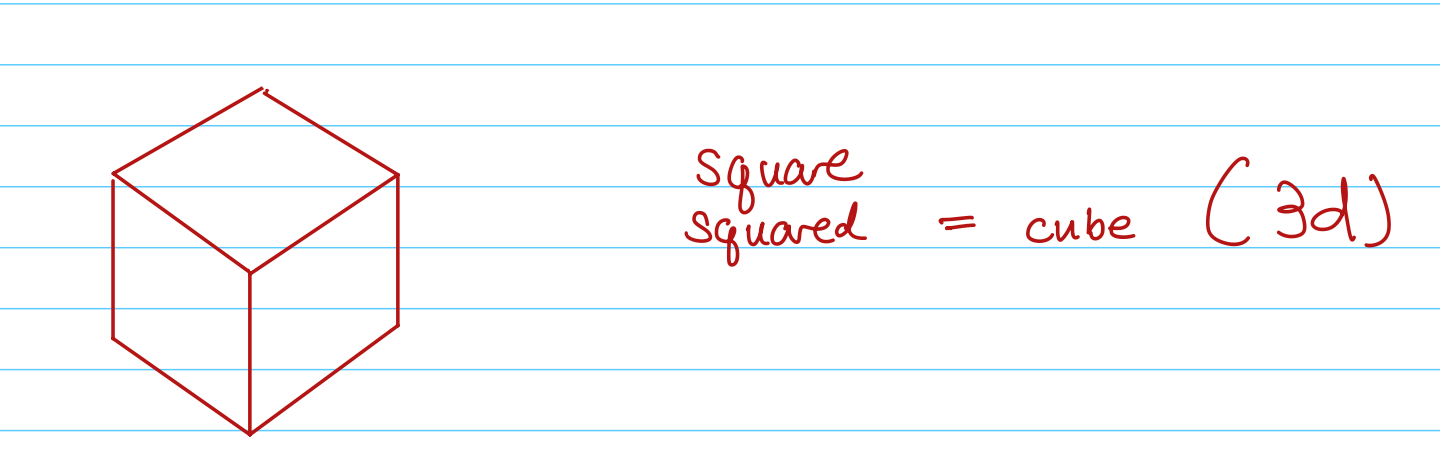
We can’t take an Apple Pencil and draw what it would look like to do this, but it’s also possible to square this cube — to take each of the six sides and turn it into a cube. That would be 4D. In the Madeleine L’Engle children’s books, this is called a tesseract.
Likewise, that next step can be squared again. And again. Nothing beyond the 3D cube drawn here is easy to picture in your mind, but the important thing here is that you understand the concept: there are careful, defined ways of making something more and more complicated in a mathematically defined process by adding dimensions, and pretty early on, it becomes something too complex for a human mind to construct a picture to represent.
Simple Concept 2: the Pythagorean Theorem
The one thing most people remember from high school is the Pythagorean theorem: “a squared plus b squared equals c squared.” This applies to right triangles — triangles with a perfect 90 degree/right angle, and enables us to calculate the length of the line across from the right angle, the hypotenuse.


The concept to understand here is that the hypotenuse of a right triangle — any right triangle — can be calculated to a reasonable level of precision, 100% of the time, by applying the Pythagorean theorem. If you know the lengths of a and b, you can get the length of the hypotenuse.
Simple Concept 3: Three-Dimensional Shapes Can Hide Triangles
Think about a pyramid with a square base, like this one:

Imagine dropping a line from the tip of the pyramid to the center of the base, and then another line out to the edge of the base. That would form a perfect 90 degree angle, and then a line connecting them would make a hypotenuse, like the picture below. The lines marked a and b are the two legs that form a 90 degree angle, and the line connecting them, with the three hash marks, is the hypotenuse.

Look at this for a minute or two and try to help yourself see that a pyramid like this one can hold many right triangles, each with its own hypotenuse.
Now consider that this works in any 3D space. Look at the ceiling of the room you’re in, and imagine dropping a straight line to the floor and then straight out from the point it touches the floor. That’s a 90 degree angle, and a third line that connected the ceiling, at the point you dropped the line, to the end of the line on the floor, would be a hypotenuse.
I just did this, imagining a green right triangle being created by dropping a line from the ceiling to the floor in the room where I’m writing this.

The concept to understand here is that by dropping a line from a point above the ground or floor and then flat out on the floor, of any 3D shape, we can make a right triangle.
Simple Concept 4: Number Systems Let Us Locate Things in Space
You’ve probably heard of GPS coordinates, and how they use latitude and longitude to let us find anything on earth.
We can design other systems that let us locate a thing using numbers.
Here is a picture of some kids in a classroom with an (x, y) grid on the floor.

Here is a picture of an (x, y) grid. Imagine this grid painted on the ground in a big field.

Now imagine a man standing at the intersection of the (x, y) lines painted on the ground in the big field, shooting an arrow towards the upper right corner. After a few seconds, we’ll freeze the arrow in space and examine it:
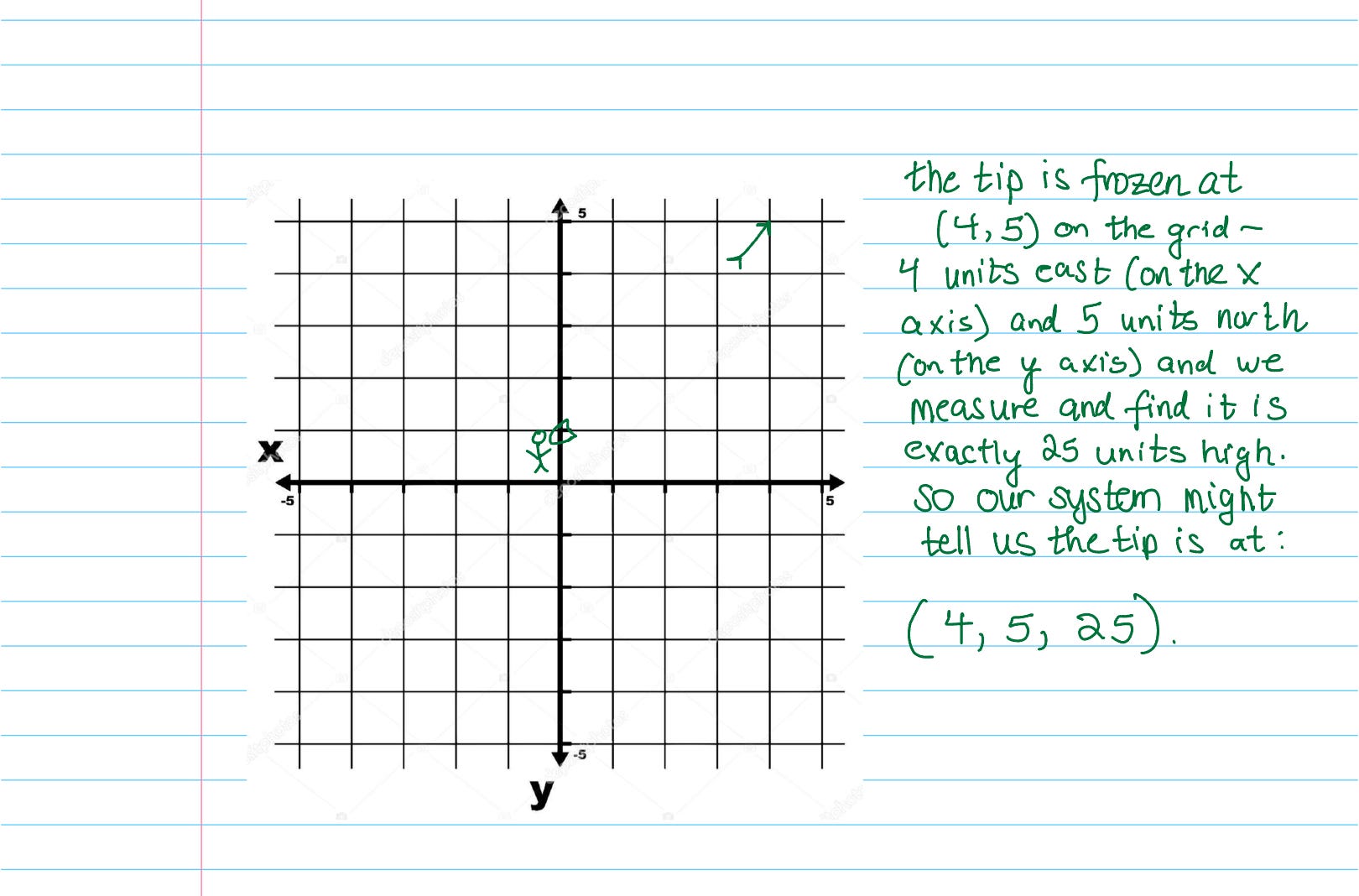
The concept to understand here is that it’s very easy to design a number system that will let a set of numbers represent both a particular point in a multi-dimensional (here, 3-dimensional) space and that point’s relationship to all the other points.
Simple Concept 5: More Data Equals Better Predictions
Imagine that you wanted to find out the average height of American men and American women.
If you only took measurements of your own family, or of the people who live on your street, you’d have some information—but not very much—and you probably wouldn’t trust your averages to represent the entire country. (You shouldn’t, anyway.)
The same dynamic would apply if you could take just a few measurements from the people on your own street, or in your own office, right? The more, the better, of course — but you wouldn’t think your data, with just ten to fifty measurements, applied to the entire country very closely.
But if you could take a sample of height measurements of 500 men and 500 women from the capital of every state, you’d have 25,000 women and 25,000 men — and you could be confident that your data was very accurate.
How the Concepts Work Together
Think about the words and concepts “hot” and “cold.” Imagine “hot” to your left, and “cold” to your right. If the word “hot” is to your left, then it’s not hard to imagine the words July, fire, shorts, and sunburn to your left, and the words January, snow, mittens, and frostbite to your right.
The word “fire” would be to your left because its meaning is very closely related to the word “hot.”
Now imagine you had to find a place for the word “floss.”
You may not know where to place it right off the bat, but it isn’t hard to understand that the words “snow” and “cold” would be closer to the word “hot” than the word “floss” would be. They’re opposites, but their meanings are related. When you’re hot, you may wish for snow so you can feel cold and thus get relief from being hot, right? There’s a relationship there that’s easier to define than the relationship between “hot” and “floss.”
So if you had to assign numbers to place these words in a predefined number system — the way that the tip of the arrow had its own space in a predefined number system — the words “snow” and “cold” would be placed closer to the word “hot” than the word “floss.”
An LLM can be thought of as an enormous shape — many, many more dimensions beyond the 3 dimensions that is easy for humans to visualize.
Inside that shape are words, which are assigned places (called embeddings) in this enormous shape. Each embedding has a set of values called weights, which are part of the model’s internal mechanisms for creating these mathematical relationships.
The weights relate to the semantic meanings of the words, as well as other factors, which are determined, either by tweaking them or not with optimization algorithms (designed by human designers, who have biases) during the training phase.
It is more complicated than I’m making it sound here, but this is the gist of it.
Built-in Bias
The extremely complicated relationship of the weights of different words in relation to other words — the way that “hot” would be very closely related to “fire” and also closer to “snow” than “floss” — forms a complex system that might be called a neural net. Like a brain, it’s extremely complex.
The neural networks and the relationships of the weights in these multi-dimensional shapes are shaped during training. Training LLMs requires access to high-powered computing that is far beyond what the ordinary computers most of us have in our homes can handle. Training an LLM would simply fry the processor of any normal computer.
I’ve trained a few LLM models by paying a fortune for access to the highest tier of GooglePro (letting me remotely access the kind of powerful computers it takes to train an LLM model) and even that is so computationally expensive that the training process would often time out. A single training epoch would sometimes take 24 hours, and that was for training a basic model only, on a pretty simple and small corpus of text. It was nothing like the process of training a true LLM like chatGPT.
The reason why LLMs have certain biases in the kinds of answers they will and won’t give is that the training phase of the model, the weights are tweaked by the designers of the model, via optimization algorithms that they built, and thus express their own biases.
But where do the built-in weights, the weights the algorithms optimize, initially come from? LLMs like ChatGPT essentially train on “the internet” itself. (This is an exaggeration, but not much of one — the datasets are vast but not the entire internet.)
This means that the responses of ChatGPT reflect both the biases of the people who designed the optimization algorithms but also the biases of the training data itself. This is why ChatGPT sucks at math but is pretty good at summarizing movies and TV — because the available training data for people doing math is significantly smaller than for people blathering about pop culture.
The starting values of the weights, which determine how closely related different words are, basically come from seeing how closely the different words are found to other words in the training data of the internet.
For much of this process, they apply the Pythagorean theorem. Similar embeddings (which contain words and numerical relationships between those words and other words, remember) are compared, and the shortest hypotenuse wins.
What this essentially means is this:
LLMs like ChatGPT, Grok, Bard, Llama, and others are basically glorified next word predictors.
They are essentially doing what your phone does when you’re texting and it gives you three choices for the next word, but on a grand, god-like scale.
That’s really all they are: god-tier next word predictors.
They are not thinking. They are not reasoning. They are not applying logic or rationality and coming to conclusions. They are simply producing extremely good guesses at the next word, because they have a ton of data — just like your guesses at the average height of American men or women would be extremely good if you were able to take a sample from the capital of all 50 states.
This lets it do some things that look very much like thinking, but they’re not.
For example, LLMs can translate pretty well, but this is just another version of what it does in English.
Imagine two distinct grids, one for each language. Words in the source language (like “hot” or “cold”) are positioned based on their meaning in relation to other words, similar to how I have already described placing words along dimensions. In translation, an LLM identifies the word's position in the source language's grid, then finds the equivalent position in the target language's grid, selecting the closest word in that context. It's like matching locations across different maps using a similar coordinate system.
This process allows the model to maintain the meaning while switching languages, even though it's just predicting the most likely next word in the target language, based on vast data.
Conclusion
It took my phone about six months to figure out that I never, ever say “Brett” in a text— I always say “Bret,” because the only person named Bret I ever send a text to, get a text from, or mention in a text, is my friend Bret Weinstein.
Over time, my phone stopped ever suggesting Brett and only suggested Bret because the individual unit of my phone’s next word predictions noticed and adjusted to my own particular usage.
Similarly, my chatGPT account answers all questions about carbs by answering strictly in net carbs. If I ask it about nature without specifying, it answers in terms of New England’s flora, fauna, weather, and terrain. If I ask it a coding question, it explains in narrative and then bullet-points the main ideas involved in the answer before it asks me if I would like to see a code sample, and if so, in what language.
Why does it do these things? Because over time my own chatGPT account has adjusted to my own particular wishes, preferences, and contexts.
None of the above constitutes “training AI” or “teaching AI” or anything of the sort.
When a homeschooling mom gets chatGPT to include Bible verses in most answers, she hasn’t “trained AI.” She’s just gotten chatGPT accustomed to the types of answers she prefers to get.
When a homeschooling dad gets chatGPT to include World War 2 references in most examples it gives, the same thing applies—he’s just gotten chatGPT accustomed to the types of answers he prefers to get.
(No shade to these parents; their misunderstandings were easy to arrive at, and I appreciate their asking me questions about it!)
Training an LLM involves access to the model’s embeddings and weights. Getting answers back that are more suited to your own particular preferences, contexts, and needs involves simple user-specific adaptations only, and these have zero effect on how anyone else will experience the LLM.
This personalization process isn’t very hard. You don’t have to ask chatGPT to give you Bible verses. You can just talk about the Bible in your questions, or otherwise consistently hint that you regard the Bible as very, very important. It will adjust and work in Biblical references and allusions over time.
Of course, you can do it directly, too — the paid accounts on chatGPT have a memory function. If you ask it to remember a thing, it will try to do so and to apply your request into its future answers.
ChatGPT can be a good way to brainstorm, or a good source for basic introduction to a topic—a place to begin to learn more.
It does not think. It does not reason. It is not capable of making judgments, only of applying built-in heuristics designed for it during the training phase.
So when you use chatGPT or other LLMs, remember that it’s a useful and fun tool, but it’s not providing you with knowledge. Its ability to solve problems relates strictly to its ability to use its knowledge of how words relate to each other semantically, not actually understanding the meanings of things.
It’s a god-tier next word predictor.
And that’s all.
Good parallel there, Holly. As a semi-retired engineer with 43 years in tech, I find it troubling when all manner of otherwise well educated folks start stirring up fear over how AI "thinks" and will become "self-aware" at some point and we should be enacting all kinds of laws etc.
The problem with fear mongering is that it elicits unwarranted actions. This is twofold; first people begin to think of LLM's and 'AI' as truly reasoning appliances, second, government LOVES to get their hoary paws into anything, and fear provides the requisite smoke screen to enact cumbersome and unnecessary restrictions to prop-up more intrusive and ever-expanding authority.
There are truly massive gaps in the public and scientific understandings of what truly is 'consciousness' and what accounts for 'reasoning' and 'thinking' -- I think you did well to touch on those. Personally, I think more distinctions are required--folks need to come to the understanding that our ability to think, reason and come to understandings can never be replicated by LLM's or AI, so-called.
I think that the biggest threat "AI" poses is in the attribution of more "respect" to it than it rightly deserves. This tends to drive the gullible into using its 'answers' to make important decisions (and take commensurate actions) without our using true critical thinking skills.
Nicely done Holly. I find myself constantly explaining to people that LLMs (which as you rightly say have become ubiquitously referenced as AI) are still computer algorithms that require logic and data and training. They are not reasoning. They are not sentient. They are gathering, sorting, and returning their best algorithmic guess. Thanks for this great write up!